User Stories: Definition, Structure, and 2026-Proof Techniques to Write High-Quality Agile User Stories
A user story is the most practical way to express product requirements in Agile because it frames work around an identifiable user, a concrete intent, and a measurable outcome. Teams rely on user stories to translate strategy into an executable product backlog without locking themselves into premature solutions, which keeps delivery flexible while preserving clarity on value. In 2026, product organizations operate in tighter feedback loops and higher delivery cadence, so the ability to write stories that are both understandable and testable becomes a competitive advantage for quality, speed, and stakeholder trust. A strong user story improves alignment between Product Owner, engineering, design, QA, and business stakeholders by describing what success looks like, not how to implement it. When user stories are written well, they reduce rework, sharpen prioritization, and make sprint planning and refinement decisions faster because everyone evaluates the same value and constraints.
What a user story is and why it still wins in 2026
A user story is a short statement of a need told from the perspective of someone who uses the product or experiences its outcomes. Its role is not to replace detailed thinking but to sequence it: you capture the intent quickly, then refine it through discussion, examples, and acceptance criteria as the team learns more. In modern Agile delivery, user stories operate as the backbone of prioritization because they link a piece of work to user value, business goals, and measurable behaviors. This makes them more resilient than pure functional specifications when priorities shift, new insights appear, or constraints evolve mid-quarter.
User stories matter in 2026 because teams increasingly coordinate across distributed roles, automation, and AI-assisted workflows, and they need a shared language that stays human-readable. A well-written story creates a stable “unit of meaning” that can be estimated, planned, tested, and reviewed without turning into a document nobody reads. Research and practitioner surveys also highlight how fast tooling adoption is changing delivery habits; for example, the AI4Agile Practitioners Report 2026 reports that 83% of Agile practitioners use AI, even if many use it for a small portion of their work. In that context, crisp user stories help teams use automation responsibly because the intent, constraints, and acceptance signals remain explicit and reviewable by humans.
User story vs. requirement vs. task: the distinction that prevents backlog chaos
A user story is a requirement expressed as user intent and value, while a task is the implementation work needed to fulfill that intent. Confusing the two creates backlogs filled with UI elements, endpoints, or refactors that lack visible outcomes, which makes prioritization political instead of evidence-based. A requirement document may describe what must be built in detail, but a story should preserve optionality by focusing on the user goal, the context, and success criteria. When teams keep this distinction clear, they can safely add technical tasks under a story while still reporting progress in terms that stakeholders understand.
The fastest way to tell whether something is a user story or a disguised task is to ask whether you can validate it with user-facing outcomes. “Add a dropdown” is not a story because it describes a solution; “enable users to pick a delivery window” is closer because it describes behavior and value. The story anchors planning to outcomes, while tasks anchor execution to steps, and both are necessary but belong at different layers of the backlog. When you maintain that separation, you can split, reorder, and refine work without losing the product narrative that guides decisions.
The canonical user story template and how to make it actually useful
The most widely used template is: As a [role], I want [capability], so that [benefit]. This format works because it forces clarity on who needs something, what they want to do, and why it matters, which naturally drives better trade-offs when the team discusses scope. The template is not a magic spell; it is a constraint that prevents vague requests from entering the backlog without value attached. In practice, the best stories often include extra context like the scenario, constraints, and definition of success, but the core remains the same: role, intent, outcome.
To make the template useful, treat each clause as a decision tool rather than a writing exercise. The role should be a specific persona or stakeholder type with a recognizable goal, not “user” or “admin” unless those are meaningful in your domain. The “I want” clause should express capability in plain language that implies behavior, not screens or code components. The “so that” clause should describe the value in a way that a business stakeholder could prioritize and a QA engineer could test, which is why outcomes and measurable benefits outperform vague statements like “make it easier.”
How to define the “As a” role without being generic
The role is the fastest lever for story quality because it clarifies context and expectations before you discuss any solution. A good role represents a class of users with shared needs, permissions, and constraints, such as “first-time buyer,” “warehouse operator,” or “finance approver.” When you choose a role, you implicitly define what the user knows, what environment they operate in, and what success looks like for them, which keeps discussions grounded. If the role is too broad, teams compensate by stuffing edge cases into acceptance criteria, and the story becomes both harder to estimate and harder to validate.
In B2B and internal tools, roles often map to responsibilities rather than demographic personas, so name them by job-to-be-done rather than titles alone. “Customer support agent handling refunds” communicates intent better than “support user,” because it hints at workflow, urgency, and compliance constraints. If your organization uses personas, reference them consistently so the backlog remains coherent and analysis becomes easier across quarters. When roles are consistent, you can detect story patterns that indicate product friction points and prioritize improvements with better evidence.
How to write the “I want” clause so it stays behavior-focused
The “I want” clause should describe what the user can do, not the UI element they click or the service you plan to build. Behavior-focused phrasing helps the team consider multiple designs and implementations, which increases the chance of finding a simpler solution that meets the same need. Strong “I want” statements describe an action in the user’s language, like “compare two plans,” “export transactions,” or “resume an application,” which immediately suggests testable interactions. When the clause turns technical, it becomes a solution placeholder, and you lose the creative space that Agile refinement is supposed to protect.
A reliable technique is to validate the clause with a quick “How would the user describe this?” question, then rewrite until it sounds natural. Replace “implement OAuth refresh token rotation” with “stay signed in securely without re-entering credentials,” then attach technical work as tasks or notes. This does not hide complexity; it makes complexity traceable to the user outcome that justifies it. In 2026, where teams increasingly rely on automation, story language that stays user-centric helps ensure that AI-assisted decomposition produces tasks that still align with the intended behavior.
How to craft the “so that” clause as a prioritization engine
The “so that” clause is where value becomes explicit, which is why it should express impact and not mere preference. Good value statements point to time saved, risk reduced, conversion improved, errors prevented, or decisions enabled, which makes prioritization more objective. When value is clear, teams can choose the smallest implementation that satisfies the story while preserving the intended benefit, which improves delivery speed and reduces waste. If value is unclear, teams often overbuild because they cannot tell what must be true for the story to succeed.
A practical pattern is to connect value to a product metric or business objective without turning the story into a KPI document. “So that I can complete checkout in under two minutes” provides a measurable target, while “so that I can buy faster” provides direction but less validation power. You can also encode risk-based value, like “so that we meet audit requirements,” which justifies security or compliance work that users might not explicitly request. Value statements also help stakeholders understand trade-offs, because they reveal why a story matters beyond the immediate feature request.
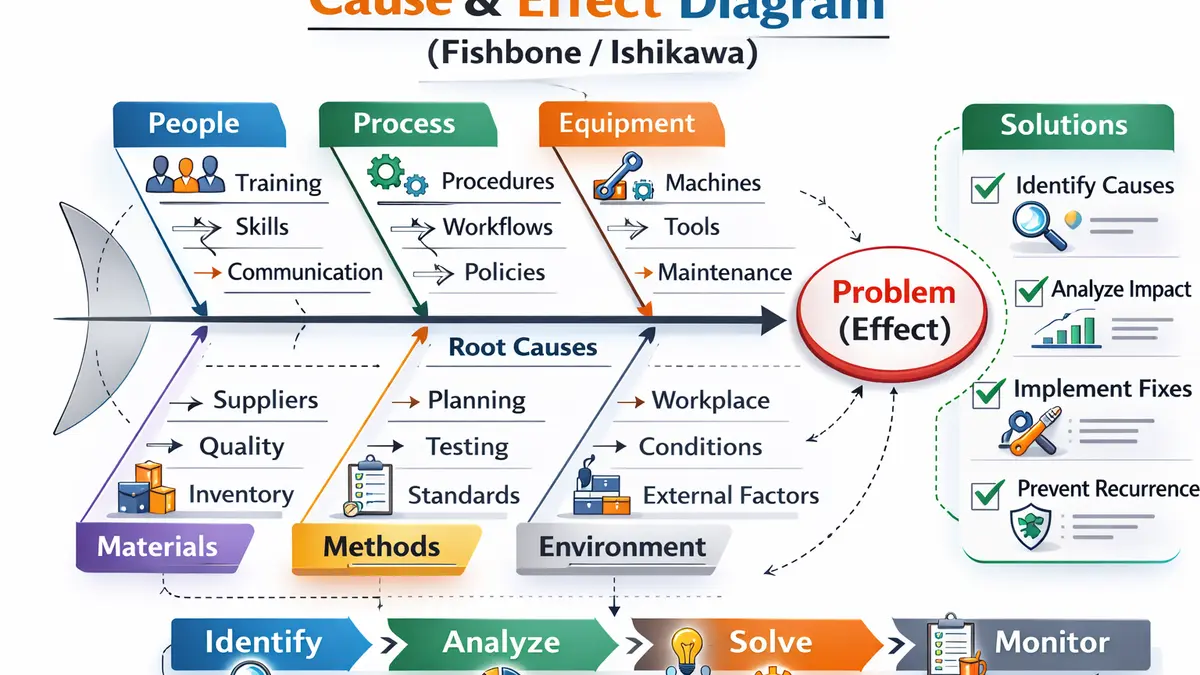
The 3Cs: Card, Conversation, Confirmation (and why teams forget the middle one)
The 3Cs framework reminds teams that a user story is not just text in a tool; it is a structured collaboration mechanism. The Card is the brief story statement that captures intent and anchors prioritization, but it is intentionally incomplete because it must invite discussion. The Conversation is where the team explores scope, dependencies, constraints, and user experience, turning a vague idea into a shared understanding that can be built. The Confirmation is the set of acceptance criteria and examples that define what “done” means for the story, so the team can validate delivery without debate.
Teams often skip the conversation because it feels slower than jumping into tasks, but it usually costs more time later through rework and defect cycles. A useful conversation is not a meeting for its own sake; it is a guided exploration that produces decisions and testable statements. The story becomes a boundary object that different disciplines can interpret consistently, which reduces misunderstandings when designers, engineers, and QA work in parallel. When you operationalize the 3Cs, the story becomes a reliable contract of intent and outcomes rather than a static requirement snippet.
Conversation techniques that produce clarity without bloating the story
High-performing teams use short, repeatable conversation structures to refine stories quickly while keeping documentation lightweight. One technique is to align on the happy path first, then list the top failure modes that matter, which prevents the team from drowning in rare edge cases. Another technique is to ask “What would make this unacceptable?” and convert the answers into acceptance criteria or constraints, which pushes ambiguity out of the build phase. These conversations should result in a small number of clear decisions, not a transcript of every thought, because clarity beats volume in a backlog.
To keep conversation outputs actionable, capture only what changes build decisions or validation decisions. If a detail does not affect scope, design, risk, or testing, it likely belongs in design documentation or operational notes rather than the story itself. Use examples and counterexamples to align quickly, because humans agree faster on scenarios than on abstract statements. When teams adopt that discipline, they preserve agility while still making stories sufficiently precise for estimation, implementation, and review.
Acceptance criteria: the mechanism that makes user stories testable
Acceptance criteria define the conditions a story must satisfy to be considered complete, and they protect teams from the most common source of delivery conflict: “That’s not what I meant.” Criteria turn intent into observable behavior, giving QA a target for validation and giving engineering a target for implementation decisions. Well-written criteria also make estimation more accurate because the team can see what must be true, what can be deferred, and what edge cases are in scope. In Agile delivery, criteria serve as the foundation for sprint review acceptance, release readiness, and regression testing coverage.
Criteria work best when they are concrete, minimal, and unambiguous, which typically means a small set that covers success and critical failure states. Teams often aim for 3 to 7 criteria depending on complexity, because fewer tends to be vague and more tends to be unmaintainable. Criteria should focus on outcomes, not internal implementation, because stakeholders validate outcomes and systems evolve under the hood. When acceptance criteria exist and are respected, they reduce time lost to negotiations during sprint review and improve trust between product and engineering.
Checklist vs. Given/When/Then: choose the format that matches your risk and maturity
A simple checklist is efficient when the behavior is straightforward and the team has shared domain knowledge, because it communicates requirements quickly. The Given/When/Then format, inspired by BDD and Gherkin, becomes valuable when the story has multiple paths, complex rules, or high risk, because it forces explicit scenarios. Both formats can be testable if they avoid vague language like “should be user-friendly” and instead specify measurable behavior or results. The right choice is the one that helps your team validate the story reliably without inflating documentation overhead.
In practice, many teams blend formats by using one or two Given/When/Then scenarios for critical flows and a short checklist for secondary conditions like permissions, responsiveness, or error messages. This hybrid approach keeps the story readable on mobile screens while preserving rigor where it matters. If your team automates tests, Given/When/Then scenarios make it easier to map criteria to automated checks, but they still require careful writing to avoid redundancy. Regardless of format, criteria should enable a simple question at review time: “Did we meet each condition exactly as stated?”
Acceptance criteria vs. Definition of Done: keep both, don’t confuse them
Acceptance criteria are specific to a single user story and define what success looks like for that requirement, while the Definition of Done is a team-wide quality standard applied to all work. DoD typically includes cross-cutting expectations like code review, security checks, documentation updates, monitoring, and test coverage thresholds, while acceptance criteria describe user-facing or rule-based behavior for the story. If you treat DoD as story-specific, it becomes inconsistent and hard to enforce; if you treat acceptance criteria as global, you lose precision and context. Keeping the two separate improves both quality and velocity because teams know what is always required and what is story-dependent.
A helpful way to manage this is to store the DoD as a stable checklist that travels with every story in your workflow, while keeping acceptance criteria inside the story where they can evolve with learning. During refinement, the team should confirm that criteria are sufficient to validate user value, and during implementation, the team should confirm that DoD items are satisfied before claiming completion. This structure reduces arguments at the end of a sprint, because acceptance becomes a matter of checking criteria and DoD rather than interpreting intentions. Over time, teams that separate these concepts build a healthier delivery culture with fewer “almost done” items.
INVEST: the quality filter for user stories that teams can apply consistently
The INVEST model is a compact checklist for evaluating whether a story is ready to enter a sprint without creating planning risk. It ensures stories are Independent, Negotiable, Valuable, Estimable, Small, and Testable, which maps directly to predictable delivery. INVEST is especially useful during backlog refinement because it turns subjective debate into a structured assessment of what to fix. When a story fails INVEST, the solution is rarely “try harder”; the solution is usually to clarify the user, tighten scope, add criteria, or split the story into smaller units.
INVEST also protects against the temptation to plan with large, fuzzy epics that are impossible to estimate or validate in a sprint. Small, testable stories make progress visible and measurable, which increases stakeholder confidence and allows earlier feedback from real users. Negotiability preserves optionality, which matters when constraints change mid-sprint or when new insights appear through testing. Teams that apply INVEST systematically reduce carryover work and create a backlog that behaves like a pipeline rather than a dumping ground.
INVEST checklist you can apply in under two minutes
- Independent: Can this be delivered without waiting on another story, or have we made dependencies explicit and manageable?
- Negotiable: Does the story describe intent and outcomes, leaving space for design and engineering decisions?
- Valuable: Is there a clear user benefit or business outcome stated in the story?
- Estimable: Does the team have enough information to estimate, or do we need spikes, examples, or constraints?
- Small: Can the team complete it within the sprint while meeting quality standards?
- Testable: Are acceptance criteria explicit enough to validate objectively?
Apply this checklist during refinement as a gate, not as a scorecard, and treat failures as signals to improve story structure. If a story is not estimable, add missing constraints or break it down until the uncertainty becomes manageable. If it is not small, split by workflow step, rule set, user segment, or value slice so the team can deliver a useful increment earlier. If it is not testable, rewrite criteria into observable behaviors and add one or two concrete scenarios that remove ambiguity.
From epic to sprint-ready stories: slicing techniques that preserve value
An epic is a large requirement that captures a broad capability or outcome, but it is too big to plan and deliver in a single sprint. The purpose of an epic is to hold the product narrative at a higher level while you discover the right slices of value to deliver incrementally. In 2026, teams often ship continuously, so the ability to break epics into shippable stories is essential to maintain momentum and learning. The goal of slicing is not to create more tickets; it is to deliver meaningful increments sooner and reduce the risk of building the wrong thing.
Effective slicing keeps the user outcome intact while reducing scope, which means each slice should still produce a coherent user-visible improvement. When teams slice by technical layers, they often end up with stories that deliver no user value until the last slice, which delays feedback and increases risk. Instead, slice by workflow step, business rule, user segment, or level of sophistication, ensuring each story is independently valuable. This approach supports better prioritization because stakeholders can choose which value slice matters most right now.
Five slicing patterns that work across consumer apps, B2B SaaS, and internal tools
Slicing works best when you choose a pattern that matches how users experience the product rather than how engineers structure the code. Workflow slicing delivers step-by-step capability, such as “create draft,” then “submit,” then “approve,” which fits business processes and permissions. Rule slicing adds complexity progressively, such as “flat tax,” then “tiered tax,” then “jurisdiction-specific rules,” which reduces early implementation complexity. Persona slicing targets specific roles first, such as “agent view” before “manager view,” which accelerates adoption in the segment that drives the most value.
Interface slicing is useful when you can deliver value through a basic UI first, then add efficiency features like bulk actions or shortcuts. Data slicing limits scope by supporting a subset of data types or file formats early, then expanding coverage as you learn. The key is to ensure each slice includes enough end-to-end functionality to be validated in production or at least in a realistic test environment. When you slice this way, you create a backlog that supports continuous delivery and continuous learning instead of waiting for a big-bang release.
Estimation and planning: making stories measurable without turning Agile into accounting
User stories become planning assets when they are clear enough to estimate and small enough to complete within a sprint. Estimation is not about precision; it is about reducing uncertainty to a level where planning decisions are safe and trade-offs are explicit. Teams commonly use story points, t-shirt sizing, or throughput-based forecasts, but all methods depend on stable story quality. If stories vary wildly in size and clarity, the planning method becomes irrelevant because the input is noisy and unpredictable.
A practical way to keep estimation grounded is to anchor it to “what must be true” rather than “how long will it take.” Acceptance criteria and scenarios define the work surface, and the team can then compare the story to similar past stories to estimate effort. A precise quantitative metric often used in sprint tracking is the story completion ratio: if a team commits to 10 user stories and delivers 9, the completion ratio is 90%, which provides a clear signal about planning accuracy and execution stability. Used responsibly, such numbers help teams improve refinement and slicing rather than punish them for uncertainty.
How to write stories that estimate well (and why that matters for stakeholders)
Stories estimate well when they have bounded scope, explicit constraints, and acceptance criteria that reveal complexity early. If a story contains unknowns, it is better to run a short spike or add discovery tasks than to pretend the uncertainty does not exist, because hidden unknowns explode during implementation. Stakeholders benefit from estimates that are honest and stable, which requires stories that do not change dramatically after planning. When you refine stories properly, you protect the sprint goal and reduce the amount of work that rolls over, which increases trust and improves long-term forecasting.
To support estimation, keep stories “small but complete” by ensuring they include enough context to make decisions without requiring another meeting. Clarify dependencies and external constraints, such as third-party integrations, regulatory requirements, or data availability, because these factors influence risk more than lines of code. Avoid combining unrelated outcomes in one story, because it creates estimation ambiguity and makes acceptance decisions messy. When stories estimate well, planning becomes faster, sprint commitments become more reliable, and delivery metrics reflect reality rather than backlog dysfunction.
Backlog refinement: where high-quality user stories are actually made
Backlog refinement is the discipline of turning raw ideas into sprint-ready stories through clarification, slicing, and acceptance criteria. It works best as a continuous activity rather than a single meeting, because learning happens as soon as you ship and observe behavior. In refinement, the team validates that stories meet INVEST, identifies unknowns, and ensures that the next sprint has enough ready work without over-preparing months ahead. In 2026, refinement is also where teams decide what automation can generate safely and what must remain human-driven, because quality depends on shared understanding, not ticket volume.
A refinement session should produce decisions that reduce uncertainty: clarified intent, defined boundaries, and testable outcomes. If the team leaves refinement with stories that still require major interpretation, the sprint will be consumed by clarification work and scope negotiation. If the team tries to finalize everything too early, the backlog becomes brittle and outdated as priorities change. The right balance keeps the near-term backlog sharp while leaving the long-term backlog flexible, so the team can adapt quickly when evidence changes.
Definition of Ready: helpful guardrail or bureaucratic trap?
A Definition of Ready can be useful when it prevents the team from pulling ambiguous stories into a sprint, but it becomes harmful when it turns into a rigid checklist that blocks learning. Ready should represent the minimum conditions for safe execution, such as clear user value, basic acceptance criteria, and manageable dependencies. It should not require perfect detail, because stories evolve during delivery and discovery continues in parallel with implementation. The purpose is to protect focus and predictability, not to create a gatekeeping process that slows everything down.
The most effective DoR is lightweight and owned by the team, not imposed as a compliance artifact. If your DoR contains too many items, teams will either ignore it or waste time filling fields that nobody uses. Keep it aligned with your risk profile: safety-critical and regulated domains need stronger readiness signals than exploratory product experiments. When DoR is used as a tool for better conversation rather than as a bureaucratic requirement, it improves sprint outcomes without reducing agility.
Story mapping: structuring the backlog around the user journey instead of a flat list
Story mapping organizes user stories along the user journey so teams can see how work items combine into a coherent experience. Instead of reading a backlog as a random list, mapping reveals the steps users take, the decisions they make, and the outcomes they seek, which helps the team build the right sequence of value. This approach supports better prioritization because it clarifies what constitutes a usable end-to-end flow for a release or iteration. In 2026, where product teams ship frequently, story mapping is one of the best ways to avoid shipping disconnected features that do not improve the overall experience.
Mapping also helps teams define a realistic MVP by selecting the minimal set of stories required to support the primary journey. Once the MVP exists, teams can add enhancements as “thin slices” that improve efficiency, reduce friction, or expand coverage without breaking the core flow. Mapping makes dependencies visible in a user-centric way, which often reveals simpler sequencing than technical dependency graphs. When you use story mapping regularly, roadmap discussions become clearer because stakeholders see how investments translate into user outcomes.
How to run a story mapping workshop that produces usable stories
Start by identifying the primary user goal and the top-level activities that represent the journey, such as “discover,” “evaluate,” “purchase,” and “get support.” Then break each activity into steps and write stories that represent what the user needs to do at each step, keeping language consistent with your personas. Once the map exists, draw a horizontal line to mark the MVP slice, ensuring it supports an end-to-end outcome rather than isolated features. After that, add further slices that improve depth, edge cases, and performance, each slice representing a coherent improvement that can be shipped and validated.
The workshop becomes productive when it ends with clear next actions: a set of prioritized stories with acceptance criteria for the near-term slice and a backlog of future slices grouped by value. Keep the map visible in your tooling, whether through a digital board or a visualization plugin, so the team does not lose the narrative as the backlog grows. Use examples and constraints during the workshop, but avoid over-specifying implementation because mapping is about product flow and value sequence. When done well, story mapping reduces backlog entropy and makes refinement faster because the context remains explicit.
High-impact examples of user stories with acceptance criteria
Examples are useful only when they show how to encode role, intent, and value in realistic contexts, including B2B and internal workflows. A consumer example might be “As a returning customer, I want to reorder from past purchases so that I can buy frequently used items faster,” which clearly expresses a repeat behavior and a speed benefit. A B2B example might be “As a procurement approver, I want to see policy violations before approving so that we reduce compliance risk,” which expresses a decision outcome and a risk-based value. Internal tools often benefit from stories like “As a support lead, I want to tag ticket themes so that I can identify recurring issues weekly,” because it ties data capture to operational learning and prioritization.
Strong examples also demonstrate acceptance criteria that eliminate ambiguity while staying compact. For the reorder story, criteria might specify that the user can select items from the last 90 days, adjust quantities, and confirm availability before adding to cart, which are observable behaviors. For procurement approvals, criteria might specify which policy rules are checked, how violations are displayed, and when approvals are blocked versus warned, which are testable decisions. For ticket tagging, criteria might specify allowed tag types, reporting views, and access controls, which keeps implementation aligned with operational needs.
Example: checkout speed improvement with Given/When/Then scenarios
Consider a story: “As a mobile shopper, I want to save my preferred delivery address so that I can complete checkout faster.” A critical scenario can be expressed as Given/When/Then: Given the user is logged in and has at least one saved address, When they select “Buy now,” Then the default address is preselected and editable before payment confirmation. Additional criteria can specify that the user can change the default, that validation errors are shown inline, and that address changes persist across sessions. These statements stay user-focused while producing precise validation outcomes for QA and stakeholders.
This scenario also helps engineering make implementation decisions without guessing intent, because the outcome is explicit: preselection, editability, and persistence are required. If security or privacy constraints exist, you can add criteria like “addresses are not exposed in shared device contexts,” which binds the story to compliance expectations. The story remains small enough for a sprint if you limit scope, for example by supporting domestic addresses first and adding international formatting later as a separate slice. This structure demonstrates how Given/When/Then can drive clarity without turning the story into a spec document.
Common user story anti-patterns and how to rewrite them fast
The most damaging anti-pattern is the “solution story,” where the backlog item describes UI elements, database changes, or architectural steps without stating a user outcome. Another frequent issue is vague roles like “user” or “admin,” which hide different needs under one label and inflate acceptance criteria into a chaotic list. Teams also write stories that bundle multiple outcomes, such as “export data and email report and schedule delivery,” which destroys estimation and makes acceptance subjective. In 2026, these problems scale faster because teams move faster, so poor stories generate compounding waste through rework, bugs, and misaligned automation.
The fastest fix is to rewrite the story around a single user intent and attach technical tasks underneath rather than inside the story statement. Replace “Add a CSV export button” with “As a finance analyst, I want to export transactions to CSV so that I can reconcile them in our accounting tool,” then specify criteria about columns, date ranges, and permissions. Replace “Implement caching layer” with “As a dashboard viewer, I want reports to load in under three seconds so that I can make decisions quickly,” then create technical tasks for caching, indexing, or query optimization. This rewrite pattern preserves value, improves prioritization, and makes performance work visible as user-impacting outcomes rather than hidden infrastructure work.
A simple rewrite framework: Outcome, Constraint, Evidence
Outcome means stating what changes for the user when the story is delivered, using language that matches real behavior. Constraint means declaring the boundaries that matter, such as permissions, data scope, performance, accessibility, or compliance rules, because those shape implementation decisions and testing. Evidence means specifying how you will validate success, either through acceptance criteria, scenarios, or measurable signals like error rate reduction or time-to-complete benchmarks. When you apply this framework, stories become more consistent and easier to compare, which improves prioritization and reduces arguments about scope.
This approach also supports featured-snippet style clarity because it naturally produces concise definitions, structured criteria, and clear examples. Teams can apply it during refinement by asking three questions: what outcome do we want, what constraints must we respect, and what evidence proves success. The answers become the story statement and acceptance criteria, and tasks follow as implementation steps. When used consistently, this rewrite framework improves story quality without adding unnecessary process overhead.
Prioritizing user stories: value, risk, and learning as first-class signals
Prioritization is not about picking the loudest request; it is about sequencing stories to maximize value, reduce risk, and accelerate learning. Stories that unlock revenue, reduce operational cost, or remove critical friction points should surface early, but risk-reduction stories like compliance or security can also be urgent when they protect the business. Learning-driven stories, such as experiments and instrumentation improvements, deserve explicit space because they prevent teams from building blindly. A user-story backlog becomes a strategic instrument when each item expresses value clearly enough to be compared with others on outcomes, not on opinions.
Practical prioritization benefits from separating “must for the journey” stories from “enhancement” stories in a story map, because the MVP needs coherence before polish matters. Use constraints like deadlines, contract commitments, or regulatory timelines, but avoid turning the backlog into a calendar-driven list that ignores user impact. Tie high-priority stories to objectives and key results when possible, because it forces value clarity and avoids feature factories. When prioritization is done well, stakeholders see a rational sequence of outcomes, and teams avoid thrash caused by constant reprioritization without rationale.
A prioritization checklist that stays lightweight
- User value: Does the story remove a major pain point or enable a meaningful goal?
- Business impact: Does it affect revenue, cost, retention, compliance, or strategic differentiation?
- Risk reduction: Does it prevent failures, security issues, or legal exposure?
- Learning speed: Will it validate a major assumption or reveal what to build next?
- Effort and dependencies: Can it be delivered soon, or does it require prerequisite work?
This checklist supports consistent decisions because it balances value with feasibility and learning rather than focusing on one dimension. It is also easy to apply in stakeholder discussions because it translates technical complexity into business-relevant signals like dependencies and risk. If two stories have similar value, prefer the one that reduces uncertainty faster or unlocks other stories, because it increases overall throughput. Over time, applying a stable prioritization approach improves roadmap credibility and prevents reactive shifts driven by subjective pressure.
Tooling and documentation: how much detail belongs in the story in 2026?
Tools like Jira, Azure DevOps, Linear, or other backlog systems are containers, not quality drivers, so the goal is to capture the right detail at the right level. A story should contain enough information to implement and validate without another meeting, but not so much that it becomes stale and hard to maintain. Put stable facts, constraints, and criteria in the story, and put volatile artifacts like UI explorations or large diagrams in linked design docs or tickets that can evolve independently. This keeps the backlog readable and prevents stories from turning into miniature specifications that slow down delivery.
In 2026, teams often use AI to draft story variants, generate acceptance criteria suggestions, or propose test scenarios, but human review remains essential because context and risk judgment are domain-specific. The safest approach is to treat AI output as a starting point, then tighten language, validate assumptions, and remove ambiguity through conversation. Story quality improves when the team enforces consistent naming, role definitions, and acceptance formatting, because that makes search, reporting, and reuse easier. When tooling supports the workflow instead of dictating it, stories remain clear, actionable, and durable across releases.
Mini FAQ: user stories in practice
Who should write user stories in an Agile team?
The Product Owner typically owns the backlog and is accountable for story quality, but the best user stories are shaped collaboratively by product, engineering, design, and QA. Collaboration matters because each discipline sees different risks and constraints, and early alignment prevents late-stage surprises. Engineers often improve stories by spotting hidden complexity and dependencies, designers improve them by clarifying user context and interaction expectations, and QA improves them by translating intent into testable criteria. When story writing becomes a shared practice rather than a solo activity, quality rises and refinement time drops because the story already reflects multi-disciplinary insight.
How big should a user story be for a sprint?
A user story should be small enough to be designed, built, tested, and reviewed within the sprint while meeting the team’s Definition of Done. If the story repeatedly carries over, it is usually a sign that scope is too broad, acceptance criteria are unclear, or dependencies were underestimated, and splitting is the correct response. Teams often aim for a story size that allows multiple stories to complete per sprint, because that improves flow and reduces the risk of a single blocked item consuming most of the sprint. The best size is not universal; it depends on team capacity, domain complexity, and the maturity of refinement, but “small and testable” remains the practical target.
What is the difference between a user story and a technical task?
A user story describes an outcome for a user and the value created by achieving that outcome, while a technical task describes work steps that help deliver that outcome. Stories are validated through acceptance criteria and user-visible behavior, whereas tasks are validated through completion of implementation steps like refactoring, configuration, or infrastructure changes. Technical tasks belong under a story when they directly support its delivery, but they can also exist as standalone items when they deliver clear user value through quality improvements such as performance, reliability, or security. Keeping stories outcome-focused and tasks implementation-focused prevents the backlog from becoming a list of internal activities disconnected from product value.
How many acceptance criteria should a user story have?
Most teams find that 3 to 7 acceptance criteria is a practical range that preserves clarity while keeping the story readable, but the correct number depends on complexity and risk. Too few criteria often means ambiguity, while too many criteria often means the story should be split or that edge cases are being bundled unnecessarily. A good set of criteria covers the primary success behavior, the most important failure modes, and key constraints such as permissions, accessibility, or performance. If criteria become long, consider moving complex scenarios into Given/When/Then examples and keeping the remaining conditions as a short checklist.